Missing Data Our View of the State of the Art
Missing Data can occur when no information is provided for one or more items or for a whole unit of measurement. Missing Data is a very big trouble in a real-life scenarios. Missing Information can besides refer to as NA(Not Available) values in pandas. In DataFrame sometimes many datasets simply arrive with missing data, either considering it exists and was not collected or it never existed. For Example, Suppose different users existence surveyed may choose not to share their income, some users may choose non to share the address in this way many datasets went missing.

In Pandas missing data is represented by two value:
- None: None is a Python singleton object that is ofttimes used for missing data in Python lawmaking.
- NaN : NaN (an acronym for Not a Number), is a special floating-betoken value recognized past all systems that apply the standard IEEE floating-point representation
Pandas treat None and NaN equally essentially interchangeable for indicating missing or null values. To facilitate this convention, there are several useful functions for detecting, removing, and replacing null values in Pandas DataFrame :
- isnull()
- notnull()
- dropna()
- fillna()
- replace()
- interpolate()
In this commodity we are using CSV file, to download the CSV file used, Click Here.
Checking for missing values using isnull() and notnull()
In club to bank check missing values in Pandas DataFrame, we use a function isnull() and notnull(). Both function aid in checking whether a value is NaN or not. These role tin can also exist used in Pandas Series in gild to find null values in a series.
Checking for missing values using isnull()
In gild to check null values in Pandas DataFrame, we use isnull() function this function render dataframe of Boolean values which are Truthful for NaN values.
Code #1:
import pandas as pd
import numpy as np
dict = { 'Showtime Score' :[ 100 , 90 , np.nan, 95 ],
'Second Score' : [ 30 , 45 , 56 , np.nan],
'Third Score' :[np.nan, forty , 80 , 98 ]}
df = pd.DataFrame( dict )
df.isnull()
Output:
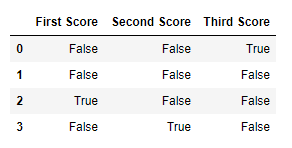
Code #2:
import pandas as pd
information = pd.read_csv( "employees.csv" )
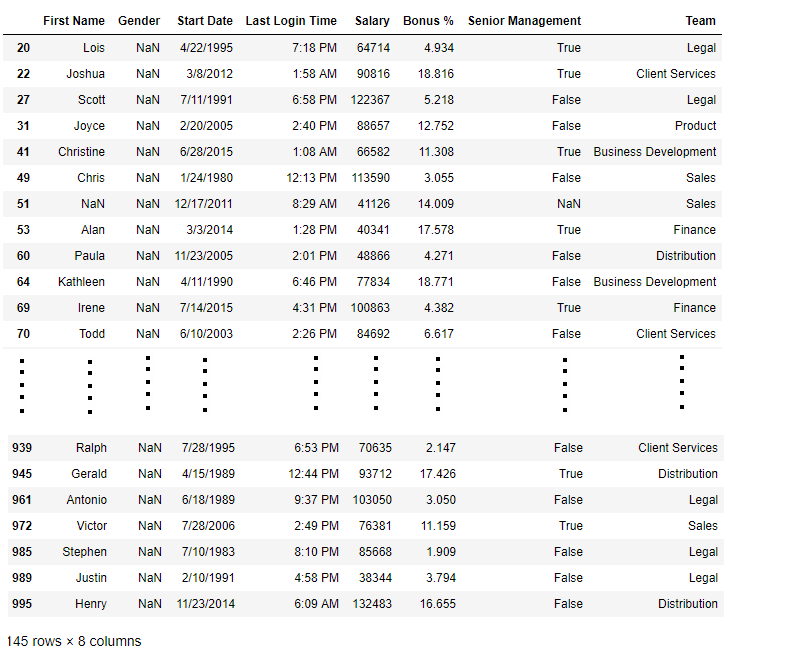
bool_series = pd.isnull(information[ "Gender" ])
data[bool_series]
Output:
As shown in the output epitome, only the rows having Gender = Aught are displayed.
Checking for missing values using notnull()
In club to check null values in Pandas Dataframe, we employ notnull() function this office return dataframe of Boolean values which are False for NaN values.
Code #three:
import pandas equally pd
import numpy as np
dict = { 'Beginning Score' :[ 100 , 90 , np.nan, 95 ],
'Second Score' : [ xxx , 45 , 56 , np.nan],
'3rd Score' :[np.nan, 40 , 80 , 98 ]}
df = pd.DataFrame( dict )
df.notnull()
Output:
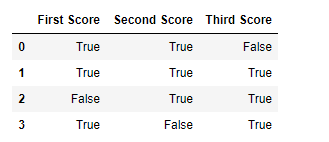
Code #4:
import pandas as pd
information = pd.read_csv( "employees.csv" )
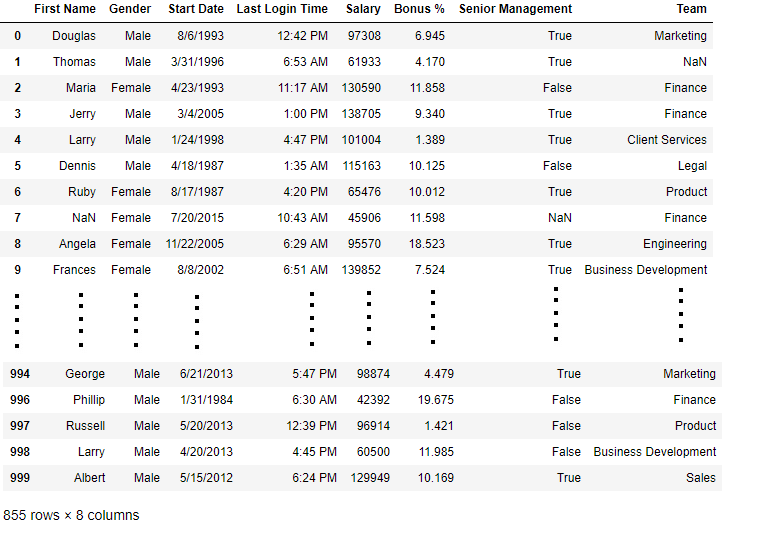
bool_series = pd.notnull(data[ "Gender" ])
data[bool_series]
Output:
As shown in the output paradigm, but the rows having Gender = NOT Nada are displayed.
Filling missing values using fillna(), replace() and interpolate()
In order to fill nil values in a datasets, nosotros utilize fillna(), supplant() and interpolate() part these role replace NaN values with some value of their ain. All these function assist in filling a null values in datasets of a DataFrame. Interpolate() part is basically used to fill up NA values in the dataframe but it uses various interpolation technique to fill the missing values rather than difficult-coding the value.
Code #1: Filling null values with a unmarried value
import pandas as pd
import numpy as np
dict = { 'First Score' :[ 100 , 90 , np.nan, 95 ],
'2d Score' : [ 30 , 45 , 56 , np.nan],
'Third Score' :[np.nan, twoscore , 80 , 98 ]}
df = pd.DataFrame( dict )
df.fillna( 0 )
Output:
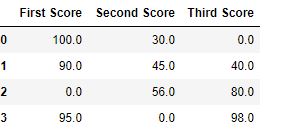
Code #2: Filling goose egg values with the previous ones
import pandas as pd
import numpy as np
dict = { 'First Score' :[ 100 , 90 , np.nan, 95 ],
'Second Score' : [ thirty , 45 , 56 , np.nan],
'Third Score' :[np.nan, 40 , 80 , 98 ]}
df = pd.DataFrame( dict )
df.fillna(method = 'pad' )
Output:
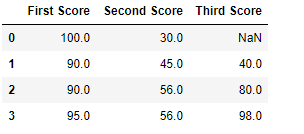
Code #iii: Filling null value with the next ones
import pandas as pd
import numpy as np
dict = { 'First Score' :[ 100 , 90 , np.nan, 95 ],
'2nd Score' : [ 30 , 45 , 56 , np.nan],
'Third Score' :[np.nan, 40 , 80 , 98 ]}
df = pd.DataFrame( dict )
df.fillna(method = 'bfill' )
Output:
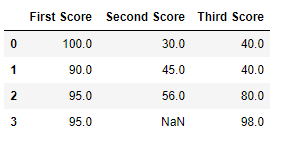
Code #4: Filling naught values in CSV File
import pandas as pd
data = pd.read_csv( "employees.csv" )
information[ 10 : 25 ]
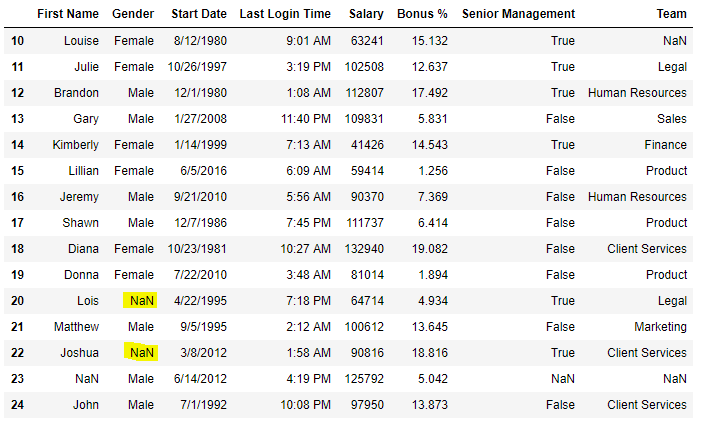
Now we are going to fill all the cipher values in Gender column with "No Gender"
import pandas as pd
data = pd.read_csv( "employees.csv" )
data[ "Gender" ].fillna( "No Gender" , inplace = True )
data
Output:
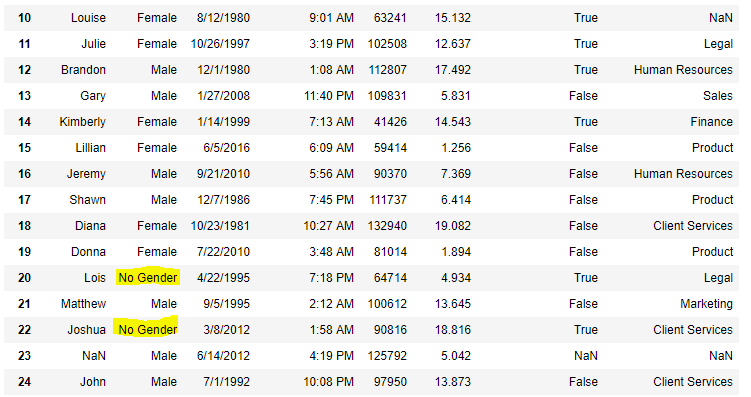
Code #v: Filling a goose egg values using replace() method
import pandas as pd
data = pd.read_csv( "employees.csv" )
data[ 10 : 25 ]
Output:
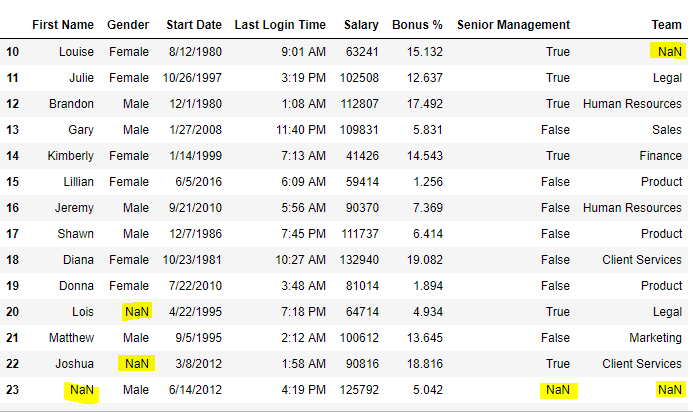
At present we are going to supplant the all Nan value in the data frame with -99 value.
import pandas as pd
data = pd.read_csv( "employees.csv" )
information.replace(to_replace = np.nan, value = - 99 )
Output:
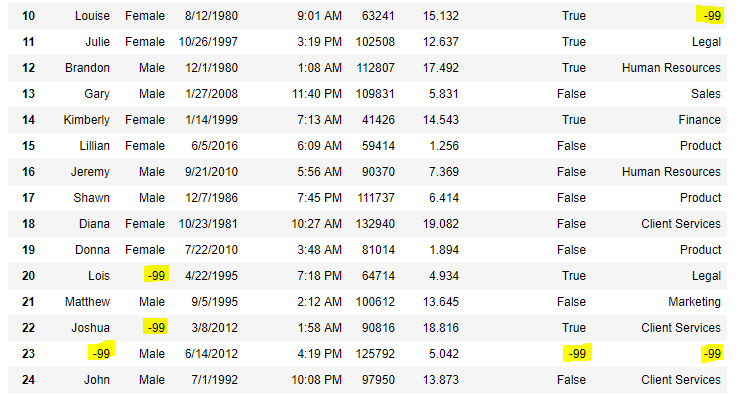
Code #vi: Using interpolate() office to fill up the missing values using linear method.
import pandas equally pd
df = pd.DataFrame({ "A" :[ 12 , iv , 5 , None , 1 ],
"B" :[ None , two , 54 , 3 , None ],
"C" :[ 20 , 16 , None , three , viii ],
"D" :[ 14 , 3 , None , None , half dozen ]})
df
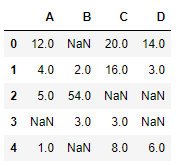
Let's interpolate the missing values using Linear method. Note that Linear method ignore the alphabetize and treat the values as equally spaced.
df.interpolate(method = 'linear' , limit_direction = 'forward' )
Output:
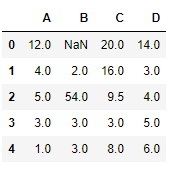
Equally nosotros can encounter the output, values in the outset row could not get filled as the direction of filling of values is forrard and in that location is no previous value which could have been used in interpolation.
Dropping missing values using dropna()
In order to drop a naught values from a dataframe, we used dropna() role this office drop Rows/Columns of datasets with Null values in different means.
Code #1: Dropping rows with at least 1 null value.
import pandas every bit pd
import numpy every bit np
dict = { 'Showtime Score' :[ 100 , 90 , np.nan, 95 ],
'Second Score' : [ 30 , np.nan, 45 , 56 ],
'Third Score' :[ 52 , twoscore , 80 , 98 ],
'Fourth Score' :[np.nan, np.nan, np.nan, 65 ]}
df = pd.DataFrame( dict )
df
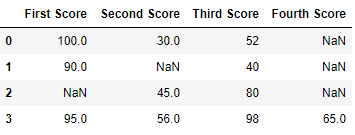
Now we drop rows with at least 1 Nan value (Null value)
import pandas as pd
import numpy every bit np
dict = { 'Get-go Score' :[ 100 , ninety , np.nan, 95 ],
'Second Score' : [ 30 , np.nan, 45 , 56 ],
'Third Score' :[ 52 , twoscore , 80 , 98 ],
'Fourth Score' :[np.nan, np.nan, np.nan, 65 ]}
df = pd.DataFrame( dict )
df.dropna()
Output:

Code #two: Dropping rows if all values in that row are missing.
import pandas as pd
import numpy every bit np
dict = { 'First Score' :[ 100 , np.nan, np.nan, 95 ],
'Second Score' : [ 30 , np.nan, 45 , 56 ],
'Third Score' :[ 52 , np.nan, 80 , 98 ],
'Quaternary Score' :[np.nan, np.nan, np.nan, 65 ]}
df = pd.DataFrame( dict )
df
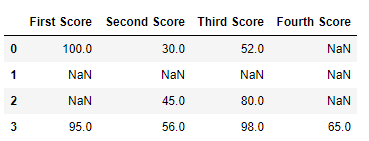
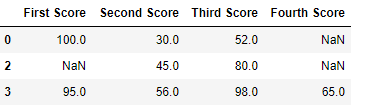
Now we drop a rows whose all data is missing or contain null values(NaN)
import pandas equally pd
import numpy every bit np
dict = { 'First Score' :[ 100 , np.nan, np.nan, 95 ],
'2nd Score' : [ 30 , np.nan, 45 , 56 ],
'Tertiary Score' :[ 52 , np.nan, 80 , 98 ],
'4th Score' :[np.nan, np.nan, np.nan, 65 ]}
df = pd.DataFrame( dict )
df.dropna(how = 'all' )
Output:
Code #3: Dropping columns with at least 1 null value.
import pandas every bit pd
import numpy as np
dict = { 'Start Score' :[ 100 , np.nan, np.nan, 95 ],
'Second Score' : [ thirty , np.nan, 45 , 56 ],
'Third Score' :[ 52 , np.nan, 80 , 98 ],
'Fourth Score' :[ 60 , 67 , 68 , 65 ]}
df = pd.DataFrame( dict )
df
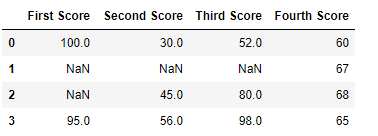
Now we drop a columns which have at least one missing values
import pandas as pd
import numpy as np
dict = { 'First Score' :[ 100 , np.nan, np.nan, 95 ],
'2d Score' : [ 30 , np.nan, 45 , 56 ],
'Third Score' :[ 52 , np.nan, fourscore , 98 ],
'Fourth Score' :[ 60 , 67 , 68 , 65 ]}
df = pd.DataFrame( dict )
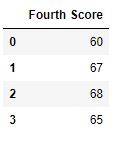
df.dropna(axis = 1 )
Output :
Lawmaking #iv: Dropping Rows with at to the lowest degree 1 nix value in CSV file
import pandas every bit pd
data = pd.read_csv( "employees.csv" )
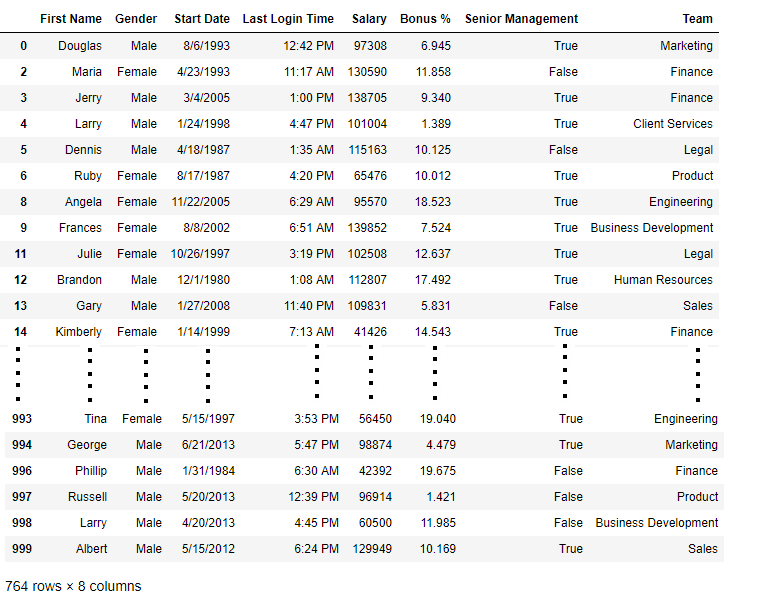
new_data = data.dropna(axis = 0 , how = 'any' )
new_data
Output:
At present we compare sizes of data frames so that we can come to know how many rows had at least ane Null value
print ( "Old information frame length:" , len (information))
print ( "New data frame length:" , len (new_data))
print ( "Number of rows with at least 1 NA value: " , ( len (data) - len (new_data)))
Output :
Old data frame length: 1000 New data frame length: 764 Number of rows with at least 1 NA value: 236
Since the difference is 236, there were 236 rows which had at least 1 Zero value in any column.
pendergrasswrife1945.blogspot.com
Source: https://www.geeksforgeeks.org/working-with-missing-data-in-pandas/
{kind=link}
Post a Comment for "Missing Data Our View of the State of the Art"